
그저 내가 되었고
🌟백엔드 개발자의 역할(DB 중심으로 서술) 본문
사족
최근 취업에 대해 본격적으로 생각하기 시작하면서 과연 '백엔드 개발자가 하는일은 무엇인가?', '신입 백엔드 개발자에게 기대하는 역량은 무엇일까?'에 대해 생각하고있다. 더불어 실전 프로젝트를 진행하며 백엔드 개발자는 DB와 상당히 밀접하게 맞닿아 있음을 절실히 느끼고 있다. 이에 백엔드 개발자와 DB의 관계에 대해 개인적인 정리 차원에서 기록을 남기고자 한다.

1. 개요
백엔드 개발자의 역할:
크게 나눠보자면 다음과 같다(실제로는 서비스 규모에 비례해서 복잡도 현저히 증가.)
- API 개발(API 서버에서 클라이언트의 요청에 응답할 수 있도록 API를 개발)
- 데이터베이스 관리(보통 API 서버는 데이터베이스와 긴밀하게 연결됨. 로그인, 회원가입, 상품 리스트 받기, 결제하기 등의 핵심 기능들은 전부 데이터베이스가 필요. 결국 백엔드 개발자는 해당 API 를 개발하면서 동시에 데이터베이스도 다뤄야 함.. 상품이라는 테이블을 만들 때는 이메일, 닉네임, 성별 등의 정보들을 저장할 수 있는 필드를 설계합니다. 이를 데이터 모델링 한다고도 이야기 함. 또한 ERD를 통해 DB 설계가 가능. API와 DB의 통신을 더 쉽게 도와주는 ORM-Object Relational Mapping- 많이 사용.)
- 서버 및 클라우드 관리(웹을 제공하기 위해서는 웹 서버 필요 + 데이터를 제공하기 위해선 데이터베이스 서버 필요 + 클라이언트와 데이터 통신을 하기 위해선 API 서버가 필요. 결국 백엔드 개발자들은 클라우드를 이용해서 서버들을 구축함. 서버를 구축한다는 말은 컴퓨터에 클라이언트에게 정보를 줄 수 있는 서버 프로그램을 설치하는 것을 의미-아무 것도 없는 컴퓨터에서 서버 프로그램을 설치하고 그 안에 개발된 코드를 실행시키는 거라고 보시면 됨- 백엔드 개발자는 서버를 구축하는 것 뿐만 아니라 효율적으로 관리하기 위해 노력 해야 함. 왜? 최소한의 비용으로 최대한의 효율을 낼 수 있다면 최고니께,,,-클라우드에서 서버를 많이 사용할수록 지불할 비용도 정비례로 증가-)
2. 서론
백엔드 개발자와 DB와의 관계:
백엔드 개발자 구직 공고를 보면 다음과 같은 DB Skill에 대한 내용을 거의 매번 마주할 수 있다.

- PostgreSQL, Oracle, MariaDB/MySQL 중 적어도 1개 이상의 데이터베이스 사용 경험 필수
- RDBMS 및 다양한 NoSQL 데이터베이스에 대한 기본적 지식이 있는 분
- DBMS에 대한 이해도가 있으신 분
- ORM을 활용하여 개발을 해보신 분
쓱 빠르게 훑어보더라도 DB에 대한 지식과 경험을 중요시함을 알 수 있다. 그렇다면 과연 어느만큼 알아야 할까?
3. 본론
3-1) 백엔드 개발자에게의 DB의 필요성:
일반적인 백엔드 개발은 반드시 DB를 필요로 한다. 어떤 비즈니스 로직이 동작함에 따라 처리하여 저장해야 할 데이터가 반드시 생기며, 그의 연장으로 해당 데이터들을 저장할 공간 역시 반드시 필요하다. 만약 이 데이터들이 메모리에 저장했는데 백엔드 어플리케이션의 결함으로 서버가 다운된다거나 하드웨어, 운영체제의 결함체제로 서버가 중단된다면 해당 데이터들은 전부 날아간다. 한마디로, 영속이 필요한 정보를 저장할 공간인 데이터베이스가 반드시 필요하다.
3-2-1) 도메인에 대한 이해와 데이터 핸들링:
개발자라면 개발하려는 해당 도메인에 대한 이해를 필수로 한다(막간 지식; 도메인:: 간단히 말하면 해결하고자 하는 문제의 영역. 소프트웨어 입장에서 다시 해석하면 개발하고자 하는 소프트웨어의 요구사항, 문제 영역 정도. 예를 들어 쇼핑몰을 만든다고 했을 때, 게시글, 댓글, 결제, 정산 등을 도메인이라고 할 수 있음.) 이러한 도메인 지식과 요구사항을 습득할 때, DB의 ERD 및 DB에 저장된 정보를 바탕으로 사용자의 어떠한 데이터를 영속화 시킬지, 데이터를 어떤 식으로 활용할지에 대한 결정은 백엔드 개발자가 담당할 일이다.
예시) Transaction
만약 계좌이체를 한다고 가정해보자.
1. A의 계좌에서 돈이 출금된다
2. B의 계좌에 돈이 입금된다.
트랜잭션이 없이 계좌이체 처리
A의 계좌에서 출금이 되고 RDBMS가 다운된다고 가정하면 A의 계좌에서 돈이 빠져나갔는데도 B의 계좌에 돈이 입금되지 않은 말도 안되는, 어중간한 상태가 되어 버리고 만다.
트랜잭션으로 계좌이체 처리
A의 계좌에서 출금이 된 후 문제 발생시 ROLLBACK을 하여 전부 없던일로 만들어 버릴 수 있다. 이러한 부분을 알고 있다면 비즈니스 로직을 작성할 때 굉장히 많은 도움이 된다.
3-2-2) SQL(Structural Query Language/구조적 쿼리 언어; 관계형 데이터베이스-RDBMS/Relational Database Management System-에 정보를 저장하고 처리하기 위한 프로그래밍 언어):
DB에 접근하여 데이터를 가져오기위해서는 SQL이 필요하다. 백엔드 개발자는 사용자의 데이터 또는 비즈니스 로직에 필요한 데이터를 자주 다루는데 이를 위해서는 기본적인 SQL 문법을 알고 있어야 한다. DB마다 가지고 있는 특정한 기능들이나 조금씩 다른 문법들은 공식 문서나 자료를 찾아볼수 있어야 한다.
3-2-3) RDBMS와 NoSQL DB, DB 선정 능력:
자신이 서비스하려는 데이터의 특성을 파악하는 작업은 DB 뿐만 아니라 개발에도 영향을 미치는 중요한 키포인트가 될 수 있다.
- 데이터 성향
- 데이터 처리양보다 무결성이 중요할 때
- 속도가 최우선 일 때
- 복잡한 Join 쿼리나 트랜잭션이 보장되어야 할 때
- 데이터의 원장성이 보장되어야 할 때
- DB의 확장 가능성을 염두해야할 때
- 서비스 성향
- 검색 조건의 다양화가 필요할 때
- 압도적인 성능(조회)이 중요할 때
- 적재보다 조회가 빈번할 때
위 조건에 부합하여 DB를 선정할 때 참고하기 좋은 테이블을 첨부한다.

이외에도 고려할 수 있는 다양한 DB와 다양한 조건들이 있을 것이다. 또한 데이터의 형태, 조건이 다양한만큼 실제로 읽기, 쓰기 속도에 대한 부분은 절대적인 우위를 지닌 DB를 정의하기는 힘들다. 그러나 현재 내가 처리해야 하는 조건에 부합하여 최적화된 성능을 낼 수 있는 DB는 다양한 테스트를 통해서 정할 수 있다. 일반적인 벤치마크 지표를 참고해보면 트랜잭션 성능 테스트는 RDBMS(PostgreSQL)가 더 뛰어나고 단일 데이터의 CRUD는 NoSQL(MongoDB)가 더 뛰어난 성능을 보인다고 한다.
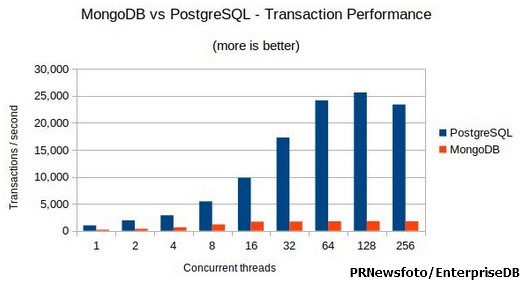

하지만 MongoDB에서도 인덱스의 데이터가 커질수록 Insert 성능이 저하되기 때문에 적정 기준을 정해야 할 것이다.

또한 꼭 RDBMS, NoSQL DB를 하나만 선택하여 사용할 필요는 없다. 상황에 맞게 RDBMS와 NoSQL DB를 혼합하여 사용함으로써 서로가 가지는 단점들을 극복하기도 한다. 실제로 결제와 같은 데이터 정합성이 중요한 부분에는 RDBMS를 사용하고 그 외에는 MongoDB를 사용하여 성능과 안정성을 모두 개선하는 경우도 있다.
3-2-4) DB 튜닝 능력:
DB 튜닝이란, DB의 성능 향상을 목적으로 수행하는 모든 작업을 일컫는다. 이는 시스템 운영 전반에 걸쳐서 다양한 분야에서 수행할 수 있다.
DB 튜닝 방안:
1) 디스크 I/O를 줄인다.
디스크로의 접근 횟수를 줄이는 것이 효과적인데, I/O를 줄이는 방법은 크게 캐시를 사용하는 방법과 DB를 분산하여 데이터 저장시 각 DB가 받는 I/O를 줄이는 것이 효과적이다.
2) 적절한 캐시를 사용한다.
버퍼 캐시 사용, 공유 메모리 설정, 가상 메모리 사용 지양 등의 RDBMS에서 제공하는 다양한 캐시 기능을 사용하여 직접적인 디스크 접근을 줄이는 것이 효과적이다.
3) 최적화 작업을 수행한다.
아래와 같은 데이터를 확보하고 분석하여 최적화 작업을 수행한다.
- SQL문 정보 (어떤 테이블이지 조건(WHERE)인지, 관계(JOIN)인지 여부) 파악
- 데이터 양, 분포 등의 작업량을 예측하기 위한 통계 정보
- 풀 스캔시 한번의 I/O 로 처리하는 블록의 갯수
- 데이터 처리 속도를 기반으로 현재 CPU 클럭, I/O 성능 등을 파악
4) SQL문 수정 및 인덱싱 처리를 해준다.
잘못된 Join 등의 비효율적인 SQL문을 수정하고 FullText(전문) 검색을 지양하고 적절한 인덱싱 처리를 한다.
위 튜닝 방안 중 개발자 수준에서의 튜닝은 3-1-4. 정도가 될 것이고 나머지는 DBA 와 같은 전문 DB팀에서 고려해야 할 것이다.
5) 효율적인 인덱싱 기준
- 하나의 값에 인덱싱을 구성 한다면 고유한 값을 가지는 컬럼(카디널리티가 높은)을 지정한다.
- 복합 컬럼에 인덱싱을 구성 한다면 카디널리티가 높은 -> 낮은 순으로 지정한다.
- 인덱스로 지정된 컬럼은 컬럼명 그대로 사용해야 한다.
- 범위 조건(between, like 등)이 아닌 곳에 인덱스를 사용하는 것이 좋다.
- 조회하려는 데이터가 전체 데이터의 약 15% 이하일 때 효과적이다.
4. 결론
지금은 바야흐로 빅데이터의 시대이다. 데이터의 양이 기하급수적으로 늘어나는 경우가 비일비재하다. 개발자라면 자신이 처리해야하는 데이터의 유형, 규모, 서비스 성향 등에 따라 적절한 Database를 선정하고 서비스 중에 데이터를 저장하고 조회하는데 있어서 발생할 수 있는 여러 사이드 이펙트를 반드시 고려할 수 있어야 한다.
물론 DB팀이 따로 존재하는 회사가 많다. 그러므로 DB 설계, 튜닝 등의 DB 작업은 DB팀에 전담하고 개발자는 코딩에만 집중할 수 있을 것이다. 그러나 개발을 하다보면 DB팀과 업무적으로 소통할 일도 많이 생기는데, 이때 DB에 대한 보다 전문적인 지식을 제대로 알고 있다면 상대방의 얘기를 이해하기도 또 내 얘기를 전달하기도 한결 수월해질 것이다.
Database Compare — SQL vs. NoSQL (MySQL vs PostgreSQL vs Redis vs MongoDB)
MySQL vs PostgreSQL vs Redis vs MongoDB: Comparative Study on SQL and NoSQL Databases. Performance comparison of 4 Popular Databases
medium.com
'개발 > BE 일반*개발 이야기' 카테고리의 다른 글
| 🌟신입 백엔드 개발자 기술 면접 질문&답변(21~30) (0) | 2022.12.21 |
|---|---|
| 🌟신입 백엔드 개발자 기술 면접 질문&답변(11~20) (0) | 2022.12.20 |
| 🌟신입 백엔드 개발자 기술 면접 질문&답변(1~10) (0) | 2022.12.19 |
| 🌟 취준:: for Junior BE Dev. (0) | 2022.12.15 |
| 🌟신입 백엔드 개발자 취준을 어떻게 할 것인가?🌟 (0) | 2022.11.21 |



